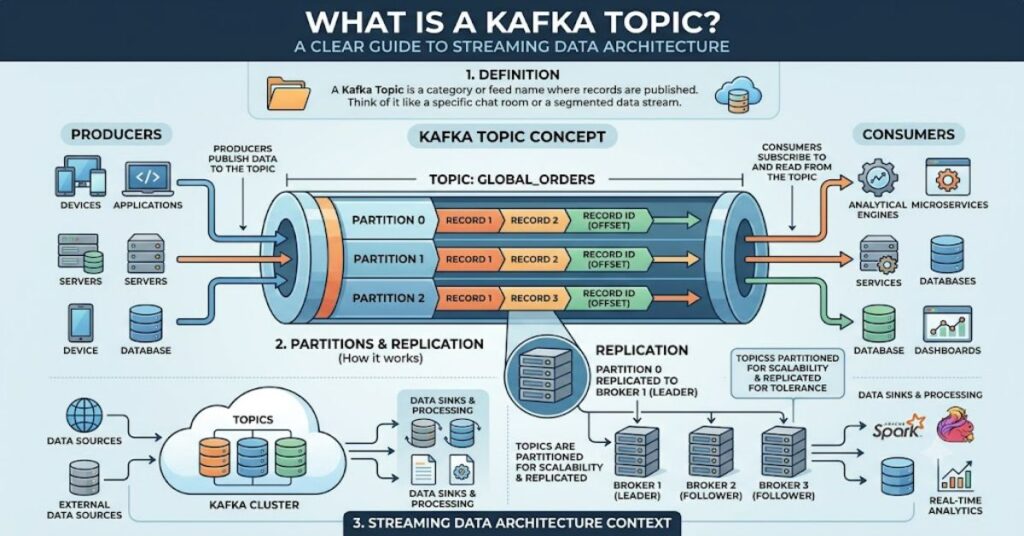
If you’re asking what is a Kafka topic, you’re essentially trying to understand the core building block of Apache Kafka’s streaming architecture. A Kafka topic is a named stream of records where data is continuously written by producers and read by consumers in real time. It acts like a digital communication channel that organizes massive flows of event data in distributed systems.
In practical terms, think of a Kafka topic as a folder in a file system. Each incoming event—such as a website click, payment transaction, or sensor reading—is a file inside that folder. Instead of static storage, however, these “files” are continuously appended and processed in real time. This structure allows systems to handle millions of events per second without breaking down or losing synchronization.
Kafka topics are central to how modern companies like Netflix, Uber, and LinkedIn process streaming data. They enable different systems to communicate without being directly connected, improving scalability and resilience. As data-driven applications grow, understanding Kafka topics becomes essential for anyone working in backend engineering, data pipelines, or cloud infrastructure.
How Kafka Topics Work
A Kafka topic is not just a storage unit—it is a distributed log. Each topic is split into partitions, which allow parallel processing.
Key Components:
- Producer: Sends data to a topic.
- Consumer: Reads data from a topic.
- Broker: Kafka server that stores topic data.
- Partition: Subdivision of a topic for scalability.
This architecture ensures high throughput and fault tolerance.
Kafka Topic Structure Explained
| Component | Function |
| Topic | Logical name for a data stream |
| Partition | Splits data for parallel processing |
| Offset | Position of a record in a partition |
| Broker | Stores and manages topic data |
Each message in a Kafka topic is assigned an offset, which helps consumers track what they have already processed.
Why Kafka Topics Matter in Real Systems
Kafka topics solve a major problem in distributed systems: decoupling services.
Without Kafka:
- Systems must communicate directly
- Failures cascade quickly
- Scaling becomes complex
With Kafka topics:
- Producers and consumers are independent
- Systems scale horizontally
- Data can be replayed or reprocessed
This makes Kafka ideal for:
- Real-time analytics
- Event-driven architectures
- Log aggregation
- IoT data processing
Comparison Table: Kafka Topic vs Traditional Queue
| Feature | Kafka Topic | Traditional Queue |
| Message Retention | Configurable | Often deleted after consumption |
| Scalability | High (partitioned) | Limited |
| Message Replay | Supported | Not supported |
| Consumer Model | Multiple consumers | Usually single consumer |
| Use Case | Event streaming | Task processing |
Kafka topics are designed for data streaming, not just task execution.
Strategic Importance of Kafka Topics
Kafka topics allow organizations to build event-driven systems, where every action becomes a stream of events.
Real-world impact:
- Financial systems process transactions instantly
- E-commerce platforms track user behavior in real time
- Logistics companies monitor shipments continuously
This shift from batch processing to streaming has reshaped modern software architecture.
Practical Example
Imagine an e-commerce platform:
- A user clicks “Buy Now”
- The event is sent to a Kafka topic called orders
- Multiple consumers process it:
- Payment service validates transaction
- Inventory service updates stock
- Notification service sends confirmation email
Each service operates independently but stays synchronized through the topic.
Risks and Trade-offs
While powerful, Kafka topics introduce complexity:
- Requires careful partition planning
- Misconfiguration can lead to data imbalance
- Operational overhead increases at scale
- Requires monitoring for lag and throughput
Understanding these trade-offs is critical before adopting Kafka in production systems.
Structured Insight Table
| Insight Area | Explanation |
| Scalability | Partitioning allows near-linear scaling |
| Fault tolerance | Data replicated across brokers |
| Replay capability | Consumers can reprocess old events |
| Ordering guarantee | Maintained only within partitions |
The Future of Kafka Topics in 2027
By 2027, streaming architectures are expected to integrate more deeply with cloud-native ecosystems. Kafka topics will likely evolve alongside managed services that reduce operational complexity.
Trends include:
- Increased adoption of serverless Kafka platforms
- Tighter integration with AI-driven event processing
- Improved auto-scaling partition management
While Kafka will remain foundational, abstraction layers will make direct topic management less visible to developers.
Key Takeaways
- Kafka topics are the core structure for streaming data in Kafka.
- They act as distributed logs for real-time event processing.
- Partitioning enables scalability and parallel consumption.
- Topics support replayable and durable data streams.
- They are essential for modern event-driven architectures.
Conclusion
A Kafka topic is more than a simple data container—it is the backbone of modern streaming systems. By organizing continuous flows of data into structured, scalable logs, Kafka topics enable real-time processing at massive scale.
Their design allows systems to remain loosely coupled while still maintaining high performance and reliability. Although they introduce operational complexity, their benefits in scalability, resilience, and flexibility make them indispensable in modern data engineering.
Understanding Kafka topics is a foundational step for anyone building or working with distributed systems today.
Frequently Asked Questions
What is a Kafka topic in simple terms?
A Kafka topic is a named channel where data is sent and stored for processing by different applications in real time.
How is a Kafka topic different from a queue?
Unlike queues, Kafka topics allow multiple consumers and support data replay, making them suitable for streaming rather than single-task processing.
Can a Kafka topic store data permanently?
Yes, data retention in Kafka topics is configurable and can range from hours to unlimited storage depending on system setup.
What is a partition in a Kafka topic?
A partition is a subdivision of a topic that allows Kafka to process data in parallel for higher performance.
Why are Kafka topics important?
They enable scalable, real-time data processing and decouple systems in modern distributed architectures.
Methodology
This article is based on established Apache Kafka documentation, distributed systems design principles, and widely adopted event-streaming architecture patterns used in production environments. The explanation is simplified for accessibility while maintaining technical accuracy.
Limitations include the absence of real-time benchmarking or proprietary system performance data, as Kafka configurations vary significantly across deployments.
Editorial Disclosure: This article was drafted with AI assistance and should be reviewed and verified by the Matrics360 editorial team before publication.